YOLO V1损失函数理解:
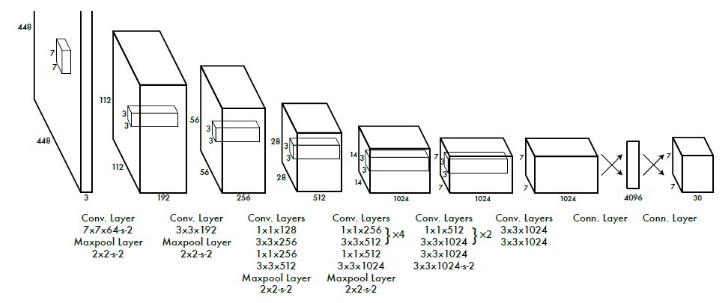
(结构图)
首先是理论部分,YOLO网络的实现这里就不赘述,这里主要解析YOLO损失函数这一部分。
损失函数分为三个部分:
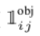 代表cell中含有真实物体的中心。 pr(object) = 1
代表cell中含有真实物体的中心。 pr(object) = 1
① 坐标误差
为什么宽和高要带根号???
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width
(主要为了平衡小目标检测预测的偏移)
② IOU误差(很多人不知道![]() 代表什么)
代表什么)
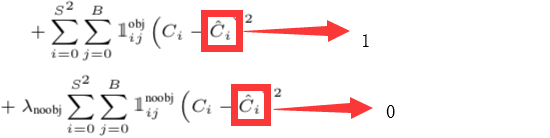
其实这里的![]() 分别表示 1 和 0
分别表示 1 和 0 ![]() =
= ![]()
③ 分类误差
这个很容易理解(激活函数的输出)。
下面给出TensorFlow的Loss代码:
1 def loss_layer(self,predicts,labels,scope='loss'): 2 ''' predicts的shape是[batch,7*7*(20+5*2)] 3 labels的shape是[batch,7,7,(5+20)] 4 ''' 5 with tf.variable_scope(scope): 6 #预测种类,boxes置信度,boxes坐标[x_center,y_center,w,h],坐标都除以image_size归一化,中心点坐标为偏移量, 7 #w,h归一化后又开方,目的是使变化更平缓 8 predict_classes=tf.reshape(predicts[:,:self.boundary1], 9 [self.batch_size,self.cell_size,self.cell_size,self.num_classes])10 predict_scales=tf.reshape(predicts[:,self.boundary1:self.boundary2],11 [self.batch_size,self.cell_size,self.cell_size,self.box_per_cell])12 predict_boxes=tf.reshape(predicts[:,self.boundary2:],13 [self.batch_size,self.cell_size,self.cell_size,self.box_per_cell,4])14 #是否有目标的置信度15 response=tf.reshape(labels[:,:,:,0],16 [self.batch_size,self.cell_size,self.cell_size,1])17 #boxes坐标处理变成[batch,7,7,2,4],两个box最终只选一个最高的,为了使预测更准确18 boxes=tf.reshape(labels[:,:,:,1:5],19 [self.batch_size,self.cell_size,self.cell_size,1,4])20 boxes=tf.tile(boxes,[1,1,1,self.box_per_cell,1])/self.image_size21 classes=labels[:,:,:,5:]22 #offset形如[[[0,0],[1,1]...[6,6]],[[0,0]...[6,6]]...]与偏移量x相加23 #offset转置形如[[0,0,[0,0]...],[[1,1],[1,1]...],[[6,6]...]]与偏移量y相加24 #组成中心点坐标shpe[batch,7,7,2]是归一化后的值25 offset=tf.constant(self.offset,dtype=tf.float32)26 offset=tf.reshape(offset,[1,self.cell_size,self.cell_size,self.box_per_cell])27 offset=tf.tile(offset,[self.batch_size,1,1,1])28 29 predict_boxes_tran=tf.stack([(predict_boxes[:,:,:,:,0]+offset)/self.cell_size,30 (predict_boxes[:,:,:,:,1]+tf.transpose(offset,(0,2,1,3)))/self.cell_size,31 tf.square(predict_boxes[:,:,:,:,2]),32 tf.square(predict_boxes[:,:,:,:,3])],axis=-1)33 #iou的shape是[batch,7,7,2]34 iou_predict_truth=self.cal_iou(predict_boxes_tran,boxes)35 #两个预选框中iou最大的36 object_mask=tf.reduce_max(iou_predict_truth,3,keep_dims=True)37 #真实图中有预选框,并且值在两个预选框中最大的遮罩38 object_mask=tf.cast((iou_predict_truth>=object_mask),tf.float32)*response39 #无预选框遮罩40 noobject_mask=tf.ones_like(object_mask,dtype=tf.float32)-object_mask41 #真实boxes的偏移量42 boxes_tran=tf.stack([boxes[:,:,:,:,0]*self.cell_size-offset,43 boxes[:,:,:,:,1]*self.cell_size-tf.transpose(offset,(0,2,1,3)),44 tf.sqrt(boxes[:,:,:,:,2]),45 tf.sqrt(boxes[:,:,:,:,3])],axis=-1) #=================================================================================================================================46 #分类损失47 class_delta=response*(predict_classes-classes)48 class_loss=tf.reduce_mean(tf.reduce_sum(tf.square(class_delta),axis=[1,2,3]),name='clss_loss')*self.class_scale49 #有目标损失(IOU)50 object_delta=object_mask*(predict_scales-iou_predict_truth) #这里iou_predict_truth应该为151 object_loss=tf.reduce_mean(tf.reduce_sum(tf.square(object_delta),axis=[1,2,3]),name='object_loss')*self.object_scale52 #无目标损失(IOU)53 noobject_delta=noobject_mask*predict_scales #这里减054 noobject_loss=tf.reduce_mean(tf.reduce_sum(tf.square(noobject_delta),axis=[1,2,3]),name='noobject_loss')*self.no_object_scale55 #选框损失(坐标)56 coord_mask=tf.expand_dims(object_mask,4)57 boxes_delta=coord_mask*(predict_boxes-boxes_tran)58 coord_loss=tf.reduce_mean(tf.reduce_sum(tf.square(boxes_delta),axis=[1,2,3,4]),name='coord_loss')*self.coord_scale59 tf.losses.add_loss(class_loss)60 tf.losses.add_loss(object_loss)61 tf.losses.add_loss(noobject_loss)62 tf.losses.add_loss(coord_loss)
YOLO V2:
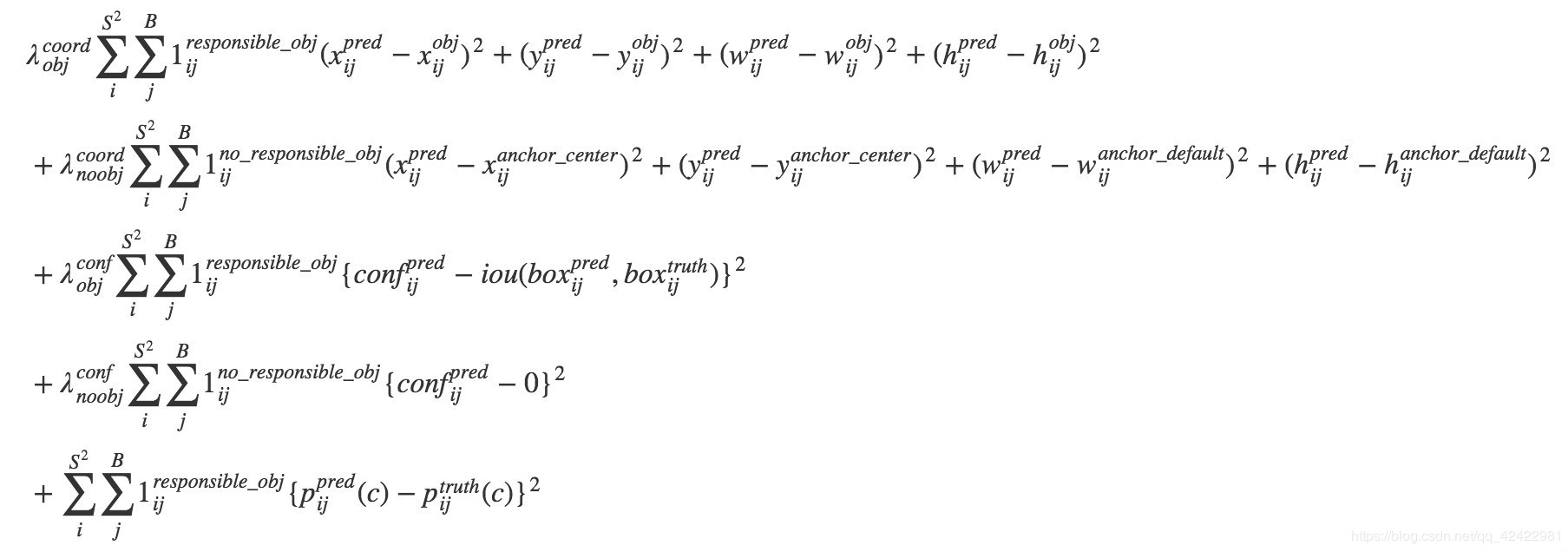
YOLO V3:
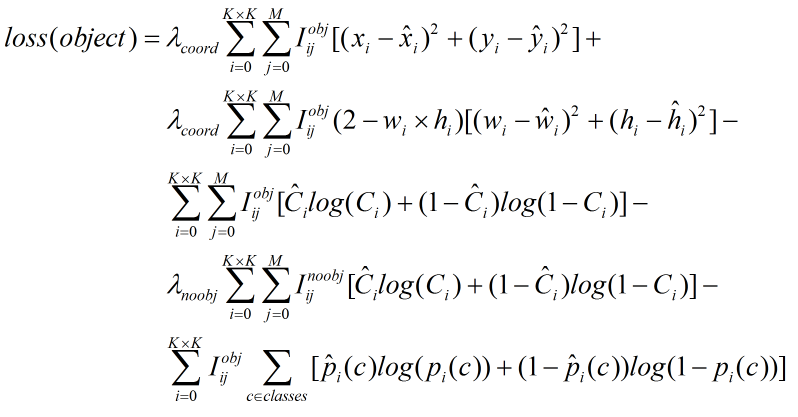
YOLOv3不使用Softmax对每个框进行分类,而使用多个logistic分类器,因为Softmax不适用于多标签分类,用独立的多个logistic分类器准确率也不会下降。
分类损失采用binary cross-entropy loss.